

Volume 15, Issue 6 And S7 (Artificial Intelligence 2025)
J Research Health 2025, 15(6 And S7): 745-760 |
Back to browse issues page



Download citation:
BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:



BibTeX | RIS | EndNote | Medlars | ProCite | Reference Manager | RefWorks
Send citation to:
Keykha A, Mojtahedzadeh R, Keramatfar A, Taghavi Monfared A, Mohammadi A. Artificial Intelligence in Evaluating the Impact of Tuition Fees on Students' Academic Decision-making. J Research Health 2025; 15 (6) :745-760
URL: http://jrh.gmu.ac.ir/article-1-2816-en.html
URL: http://jrh.gmu.ac.ir/article-1-2816-en.html
Ahmad Keykha1 

 , Rita Mojtahedzadeh2 , Abdalsamad Keramatfar3 , Ava Taghavi Monfared4 , Aeen Mohammadi5
, Rita Mojtahedzadeh2 , Abdalsamad Keramatfar3 , Ava Taghavi Monfared4 , Aeen Mohammadi5
, Rita Mojtahedzadeh2 , Abdalsamad Keramatfar3 , Ava Taghavi Monfared4 , Aeen Mohammadi5
1- Department of Educational Administration, Faculty of Psychology and Education, Kharazmi University, Karaj, Iran.
2- Department of E-learning in Medical Education, Center of Excellence for E-learning in Medical Education, School of Medicine, Tehran University of Medical Sciences, Tehran, Iran.
3- Research Center for Development of Advanced Technologies, Afta Department, Tehran, Iran.
4- Department of Educational Administration and Planning, Faculty of Psychology and Education, University of Tehran, Tehran, Iran.
5- Department of E-learning in Medical Education, Center of Excellence for E-learning in Medical Education, School of Medicine, Tehran University of Medical Sciences, Tehran, Iran. ,aeen_mohammadi@tums.ac.ir
2- Department of E-learning in Medical Education, Center of Excellence for E-learning in Medical Education, School of Medicine, Tehran University of Medical Sciences, Tehran, Iran.
3- Research Center for Development of Advanced Technologies, Afta Department, Tehran, Iran.
4- Department of Educational Administration and Planning, Faculty of Psychology and Education, University of Tehran, Tehran, Iran.
5- Department of E-learning in Medical Education, Center of Excellence for E-learning in Medical Education, School of Medicine, Tehran University of Medical Sciences, Tehran, Iran. ,
Keywords: Tuition fees, Educational financing, Academic decision-making, Artificial intelligence, Medical education
Full-Text [PDF 1578 kb]
(509 Downloads)
| Abstract (HTML) (2790 Views)
Full-Text: (115 Views)
Introduction
Over the past two decades, the financial stability of many nations has been profoundly disrupted by recurrent global crises, notably the financial collapses of 2001 and 2008. These disruptions triggered widespread economic downturns, significantly affecting public investment across multiple sectors. The higher education system has been among the hardest hit, with funding declines intensifying following the COVID-19 pandemic, a trend increasingly documented in the literature [1]. In Iran, while health policymakers have long maintained that medical education and healthcare services are public goods and thus insulated from traditional market mechanisms, the escalating burden of health expenditures and the growing public debt resulting from state obligations have progressively introduced market-oriented rationalities into health sector governance [2]. This paradigm shift has substantially impacted medical education financing, shifting the cost burden toward students and families. As a consequence, tuition fees have emerged as the primary revenue stream for many universities operating under financial constraints, particularly in low- and middle-income countries [3].
This transition has exacerbated regional disparities in educational access and affordability. More critically, the rising cost of education now directly shapes students’ academic trajectories, influencing decisions, such as program withdrawal, field switching, guest enrollment, or institutional transfer. While existing research has explored the effects of socioeconomic and demographic factors on students’ academic decision-making, the specific role of tuition fees—especially in the context of health-related higher education in Iran—remains underexamined. This gap is particularly striking given the structural transformation of university funding models in recent years and the increased volatility in students’ educational paths under financial stress. Recent advances in artificial intelligence (AI), particularly in educational data mining, offer novel opportunities to analyze such complex phenomena. AI-driven models enable the identification of subtle, non-linear patterns in large educational datasets, providing actionable insights for university governance and national policy. Among the prominent AI methods, logistic regression (LR) is valued for its interpretability, yet limited in handling complex, non-linear relationships. In contrast, artificial neural networks (ANNs) excel in modeling such patterns but often lack transparency. Decision trees (DTs) provide rule-based clarity and work effectively with categorical data but are susceptible to overfitting. Random forests (RFs), as ensemble learners, enhance predictive performance and generalizability, though they may sacrifice interpretability relative to simpler models. Despite the growing utility of these tools, tuition-driven academic decision-making has received limited empirical scrutiny within Iranian medical universities. This study aimed to fill this gap by employing comparative machine learning approaches to analyze the predictive role of tuition fees in shaping student decisions at Tehran University of Medical Sciences.
Specifically, the study investigated whether financial pressure from tuition contributes significantly to four pivotal academic outcomes: dropout, major change, guest enrollment, and institutional transfer. To guide the empirical analysis, the study proposes the following hypotheses:
H1) Tuition fees are a statistically significant predictor of student dropout. H2) Tuition fees significantly influence students’ decisions to change their academic major. H3) Higher tuition fees are associated with an increased likelihood of guest enrollment. H4) There is a significant relationship between tuition costs and the probability of transferring to another university.
By integrating AI-based modeling with the policy-relevant context of health education financing, this study offers both methodological and substantive contributions. It not only enhances our understanding of tuition-related vulnerabilities among students but also provides actionable evidence for institutional and governmental stakeholders aiming to promote educational equity and resilience.
Literature review
The relationship between tuition fees and students’ academic decisions has been the subject of substantial scholarly debate, often yielding paradoxical findings. On the one hand, researchers, such as Brooks and Waters [4] argue that rising tuition costs exert a deterrent effect on enrollment, particularly among students from disadvantaged backgrounds. On the other hand, Lan and Winters [5] report minimal or statistically insignificant impacts of tuition increases on student behavior. This divergence in empirical outcomes has prompted the emergence of conceptual frameworks, such as Heller’s “tuition dilemma” and “tuition paradox” [6], which seek to reconcile the contradictory evidence by highlighting the contextual and psychological mediators of tuition sensitivity.
Parallel to this discourse, a growing body of research has turned to AI as a means of modeling and predicting academic outcomes, particularly student attrition. AI-based predictive analytics have shown promise in uncovering latent patterns in educational data, enabling early interventions aimed at reducing dropout rates. For instance, Mubarak et al. [7] reported an accuracy rate of 84% in predicting early attrition within online learning environments using AI classifiers. Gismondi and Huisman [8] achieved a remarkable 98.97% prediction accuracy for student dropout using multilayer neural networks at the National University of San Pedro, while Agrusti et al. [9] employed deep neural networks and reported a 93.4% accuracy rate in dropout detection.
Several studies have also demonstrated the comparative advantages of tree-based algorithms. Kemper et al. [10] found that decision tree models significantly outperformed traditional LR in predicting student withdrawal behavior, attaining an accuracy of 95%. Similarly, Behr et al. [11] applied RF algorithms and achieved an 86% accuracy rate for early-stage dropout prediction. Haiyang et al. [12] utilized a time-series classification model, yielding an 84% accuracy rate in identifying dropout trajectories.
Further evidence in favor of decision tree–based approaches is offered by Limsathitwong et al. [13], who highlighted their superior performance, reporting an 80% accuracy rate. Berens et al. [14] found that dropout prediction accuracy increased over time, reaching 90% after the fourth semester in public universities, and up to 95% in universities of applied sciences. Dass et al. [15] demonstrated that RFs could accurately predict student dropout decisions in MOOC environments with 88% precision. Complementing these findings, Solis et al. [16] conducted a comprehensive comparison of machine learning models—including RFs, neural networks, support vector machines, and LR—and concluded that RFs yielded the highest predictive accuracy at 91%, offering a robust solution for identifying at-risk students.
Despite these promising advances, most existing studies have focused narrowly on dropout as a single academic outcome and have primarily been conducted in Western or online education contexts. There remains a critical gap in the literature regarding the multifaceted impact of tuition fees on a broader set of academic decisions—particularly within the context of resource-constrained, health-related higher education systems in countries, like Iran. Addressing this gap through the application of comparative AI modeling not only enhances methodological diversity but also contributes to the development of context-sensitive strategies for academic risk mitigation and policy design.
Novelty and contribution
This study pioneers a multi-dimensional, machine learning–driven framework to model the impact of tuition fees on four distinct academic decision pathways—dropout, major change, guest enrollment, and institutional transfer—within the underexplored context of health-related higher education in Iran. In contrast to prevailing research that predominantly isolates student dropout and relies on conventional statistical modeling, this work integrated a suite of advanced AI algorithms with state-of-the-art resampling strategies to address data imbalance and enhance model robustness, particularly in predicting low-frequency academic transitions.
Leveraging a longitudinal dataset from Tehran University of Medical Sciences—one of the country’s most prominent academic institutions in the health sector—the study moves beyond abstract modeling to deliver empirically grounded, policy-relevant insights. By situating tuition-related decisions within a real-world, resource-constrained environment, the research sheds light on the nuanced ways where financial pressure translates into academic vulnerability.
Furthermore, the comparative analysis of AI models not only identifies the most accurate and interpretable predictive strategies but also provides an operational framework for early-warning systems targeting at-risk students. This dual contribution—methodological innovation and practical applicability—positions the study as a significant advancement in both educational data science and policy-making for equity-driven, sustainable health education systems in emerging economies.
Methods
To empirically examine the proposed hypotheses, we employed a range of machine learning algorithms to model and predict the influence of tuition fees on key academic outcomes, including student dropout, changes in field of study, guest enrollment, and university transfer. This study systematically assessed the extent to which tuition costs shape academic decision-making by leveraging diverse AI-based modeling techniques. Figure 1 shows a diagram of the stages of the research method.
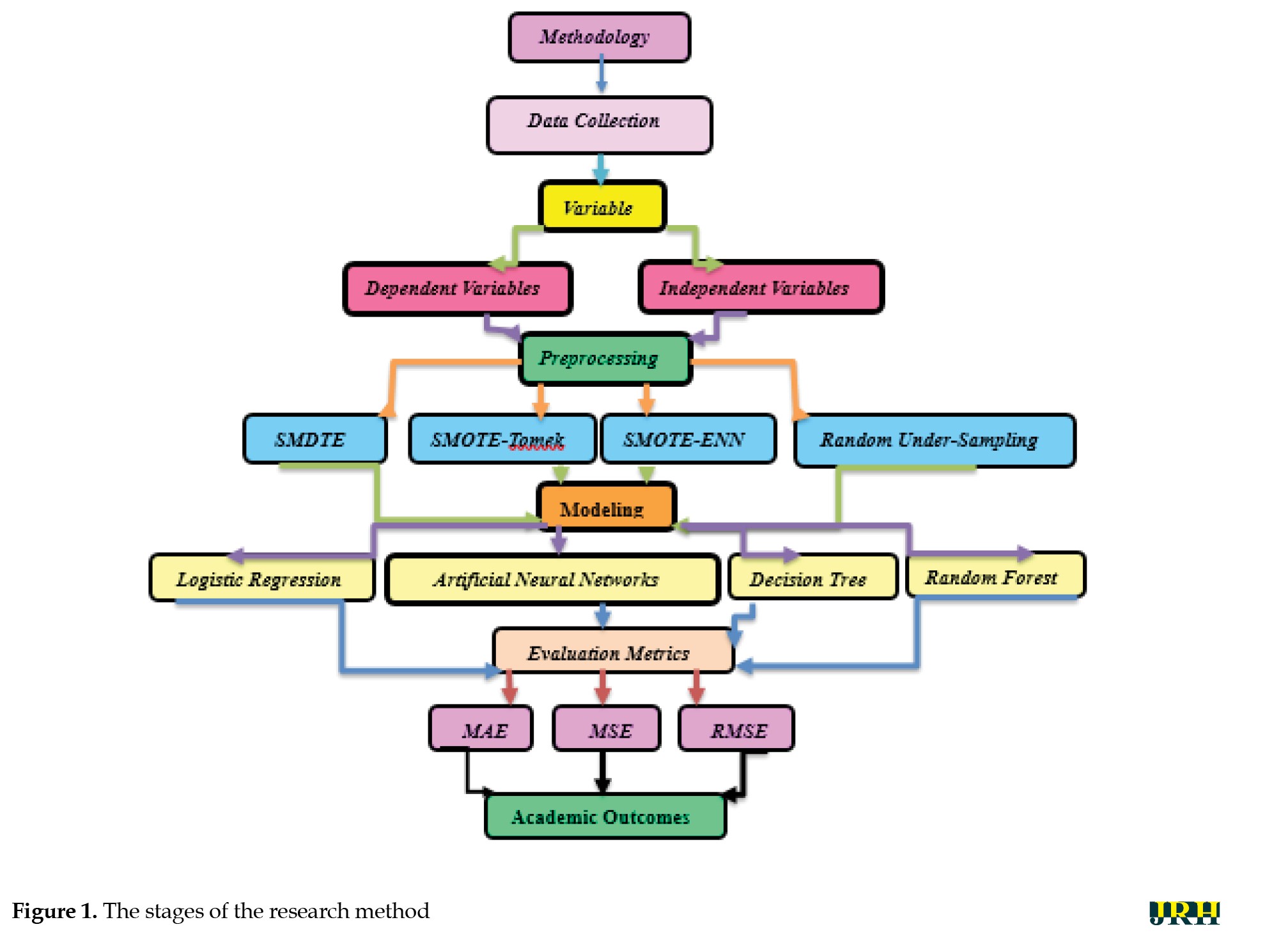
Data collection
This study utilized a longitudinal dataset encompassing the entire student population of TUMS across 12 academic schools, spanning the years 2016 to 2023. The dataset reflects the university’s institutional data collection framework and includes detailed demographic and academic records.
The number of students enrolled in each academic unit was as follows: International Campus (2,822), School of Public Health (1,917), School of Nursing and Midwifery (2,460), School of Medicine (9,326), School of Rehabilitation Sciences (954), School of Pharmacy (1,468), School of Dentistry (1,276), School of Traditional Iranian Medicine (121), School of Paramedical Sciences (1,683), School of Nutrition and Dietetics (304), School of Advanced Medical Technologies (310), and School of Research and Technology (60).
In terms of gender distribution, the dataset included 9,868 male students (43.5%) and 12,832 female students (56.5%), totaling 22,700 enrolled individuals over the eight years.
Variables
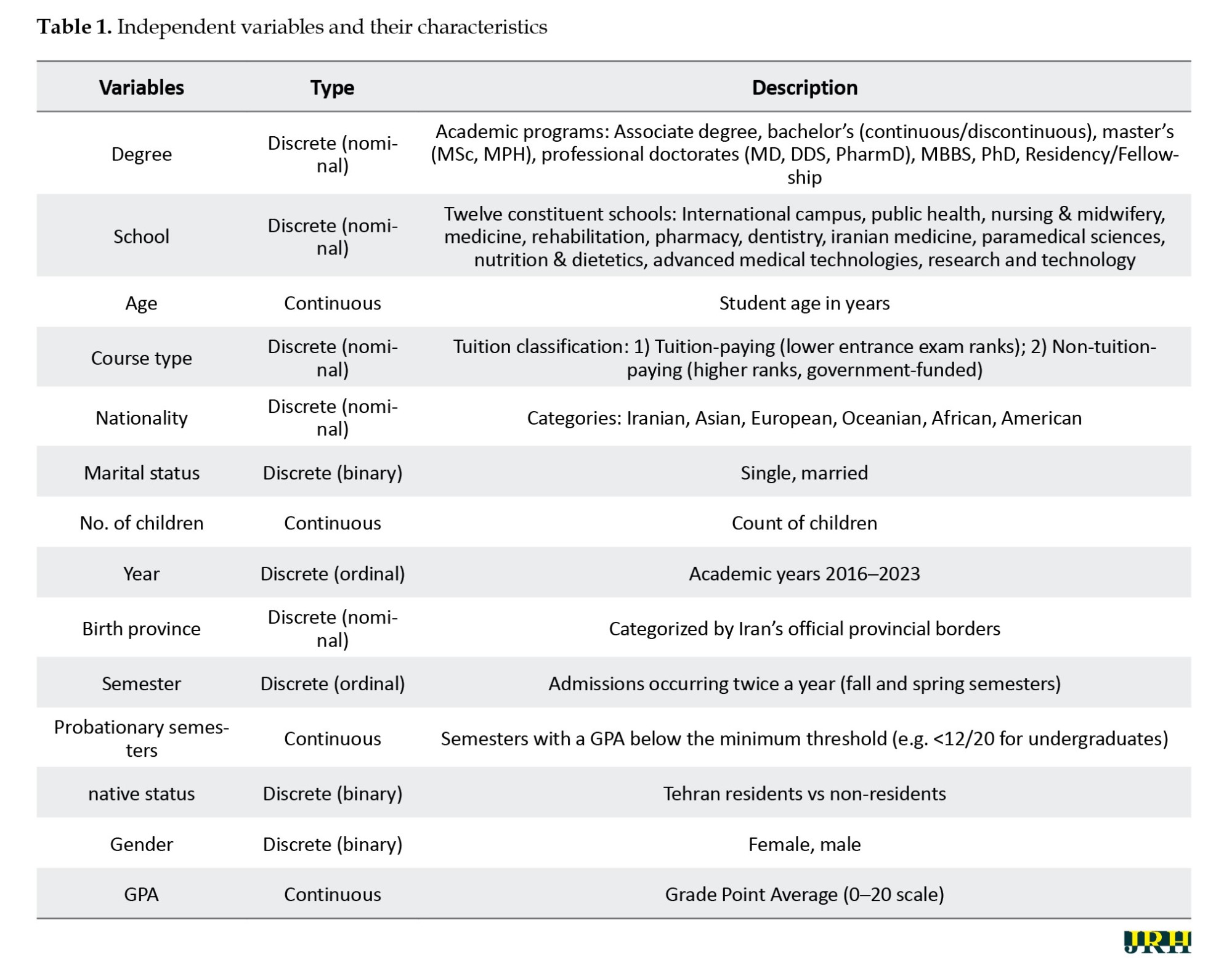
The independent variables of the study are detailed in Table 1.
The dependent variables represent key academic decisions and are structured as binary outcomes. These include:
The decision to drop out, the decision to enroll as a guest student, the decision to transfer to another institution, and the decision to change academic fields.
Evaluation metrics
To assess the performance of the classification models, three standard evaluation metrics were employed: Mean absolute error (MAE), mean squared error (MSE), and root mean squared error (RMSE). These metrics quantify the average discrepancy between predicted values and actual observations.
MAE measures the average of the absolute differences between the predicted and actual values (Equation 1):
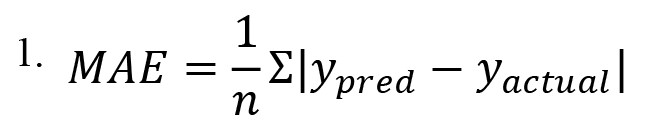
Where ypred represents the predicted value, yactual refers to the actual value, and n is the number of data points, and |x| denotes the absolute value of x. MSE measures the average of the squared differences between the predicted and actual values (Equation 2):
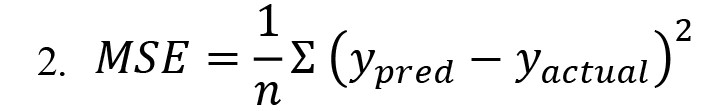
The square root of the MSE is the RMSE (Equation 3):
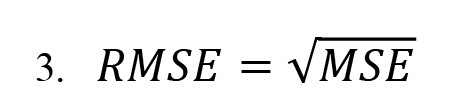
RMSE is often favored over MSE due to its superior interpretability, as it retains the same units as the dependent variable, thereby enabling more direct comparisons with observed values. Although lower values in both metrics typically reflect improved model performance, the choice of evaluation metric should ultimately depend on the specific analytical goals and contextual priorities of the study.
Algorithms used
LR
LR is a statistical modeling method used to assess the relationship between a categorical dependent variable (such as the presence or absence of an outcome) and one or more independent variables. Often referred to as a logit model, it is widely utilized in domains, such as medical diagnosis, social sciences, and predictive analytics due to its simplicity and interpretability [15].
ANNs
ANNs are data-driven modeling techniques capable of learning complex, non-linear relationships from representative datasets without requiring explicit mathematical descriptions of the underlying system. Their flexibility and adaptability make them particularly effective in reducing uncertainty and improving predictive accuracy and decision-making across a wide range of applications [16].
Decision tree
The decision tree algorithm is a supervised machine learning technique used for both classification and regression tasks. It is widely valued for its high interpretability, as it generates human-readable decision rules derived from the training data. DTs can handle various data types, including both numerical and categorical variables, and their hierarchical structure provides a transparent framework for understanding the reasoning behind predictions [17].
Random forest (RF)
RF is an ensemble learning method that constructs multiple DTs, each trained on random subsets of the data, and combines their outputs to improve prediction accuracy and robustness. By aggregating diverse models, RF mitigates the risk of overfitting commonly associated with single DTs. Although this approach enhances overall performance, it may reduce interpretability compared to individual models [18].
Given the imbalanced distribution of outcome classes in the dataset, several strategies were employed to address class imbalance. In classification tasks where the minority class is significantly underrepresented, predictive models tend to perform poorly on that class, often favoring the majority class. To mitigate this issue, the following resampling techniques were implemented:
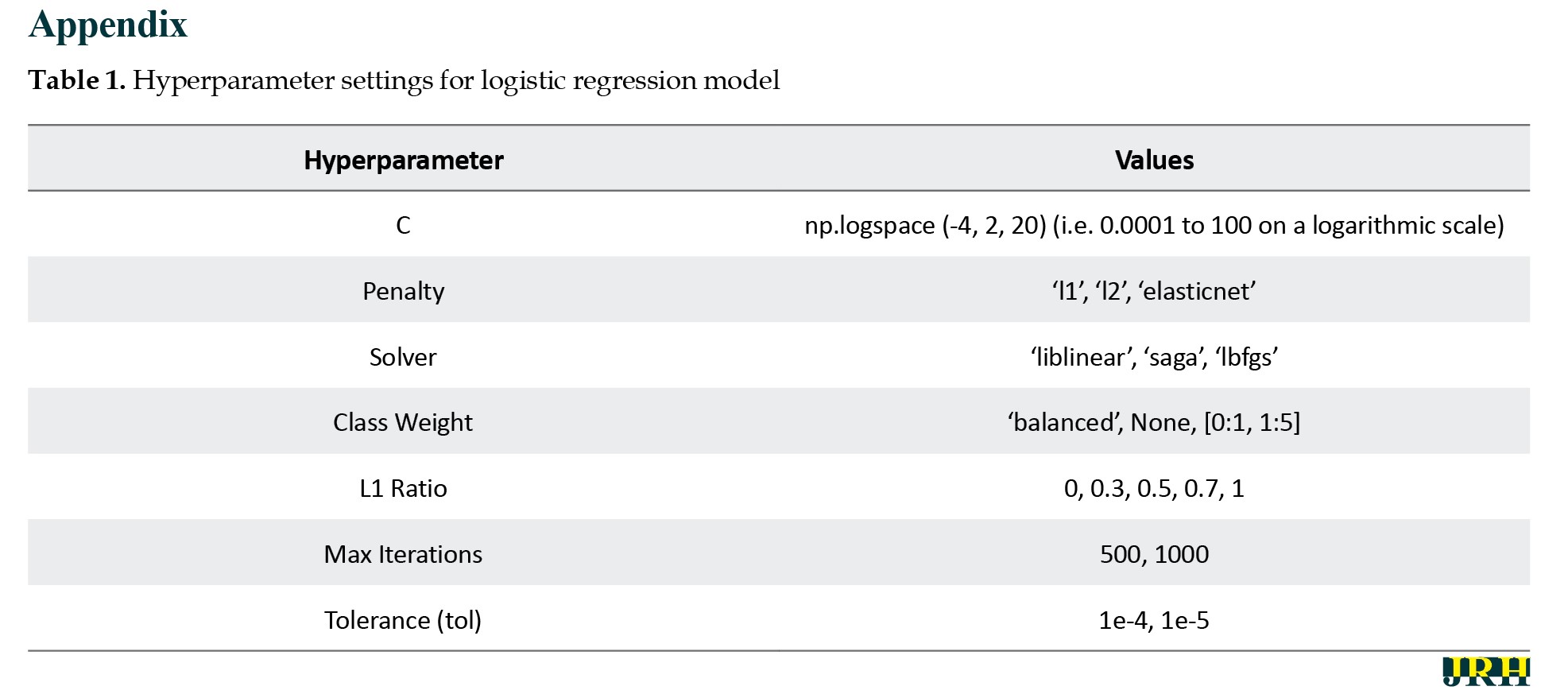
In this study, we systematically evaluated the performance of three widely used machine learning algorithms—XGBoost, LR, and RF—for predicting student academic decisions. Each model was trained using specific hyperparameter configurations (Appendix 1, 2 and 3) to ensure optimal performance.
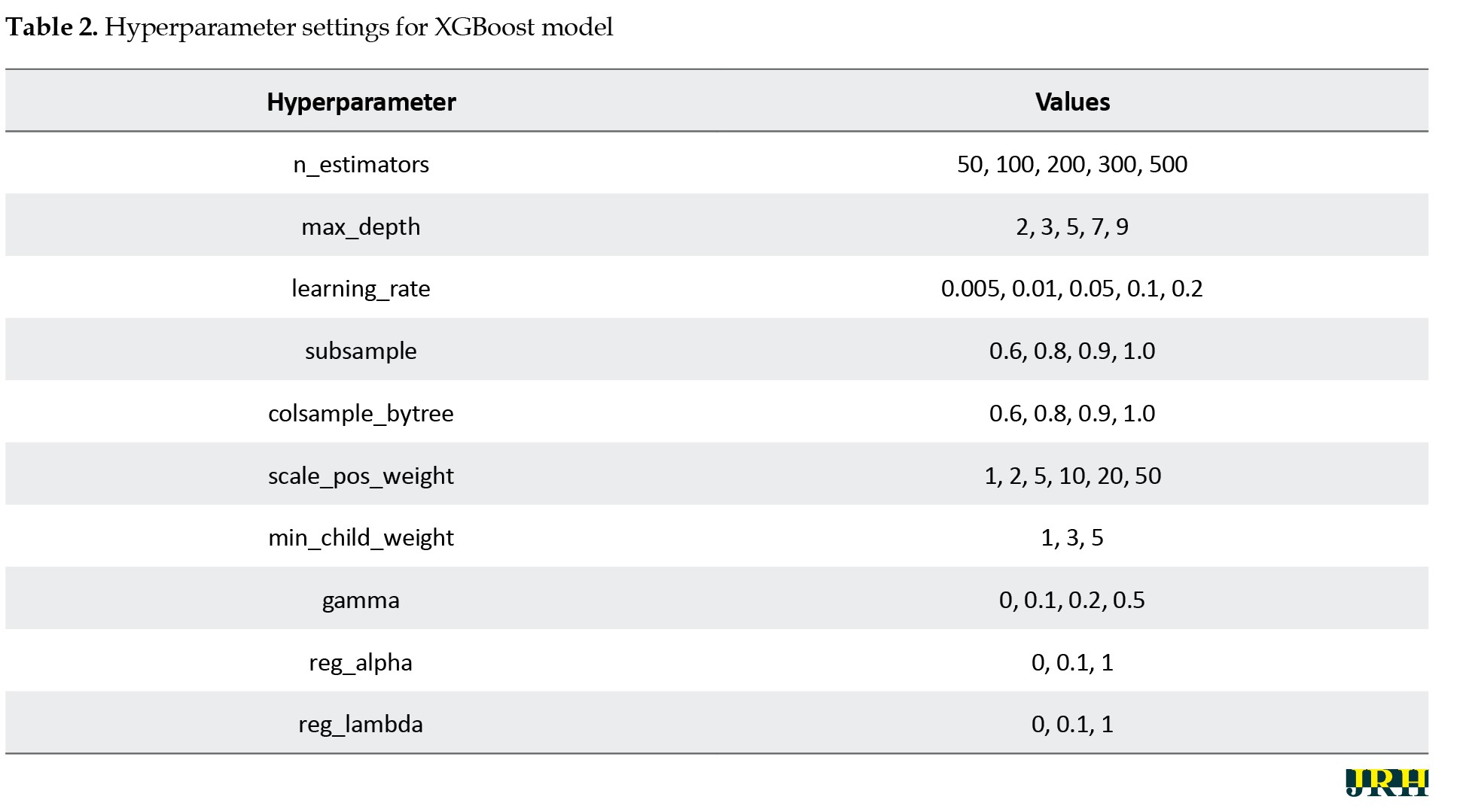

Given the inherent class imbalance in the dataset (i.e. the unequal distribution of target categories), we applied and compared five different sampling strategies to improve model fairness and accuracy. These included synthetic minority over-sampling technique (SMOTE), Tomek links (TOM), Tomek links combined with edited nearest neighbors (TEEN), random under-sampling (UNDER), and a baseline model with no sampling (none). For each combination of the model, hyperparameters, and sampling technique, we assessed predictive performance using standard evaluation metrics, and selected the best-performing configuration for each target outcome. The final models and their corresponding optimal sampling methods are reported in the Results section.
To facilitate interpretability and transparency, the models were trained on a set of well-defined parameters capturing demographic, academic, and institutional dimensions of student status. These included continuous variables, such as age, GPA, and number of probationary semesters, as well as categorical variables, such as academic degree, school affiliation, course type (tuition-paying vs free), marital status, gender, semester of entry, birth province, and native status (Tehran vs non-Tehran residents). The year of study and academic semester were treated as ordinal variables to reflect progression over time. Together, these parameters provided a comprehensive profile of each student, enabling the models to learn patterns associated with tuition sensitivity and academic decision-making in a nuanced and data-driven manner.
Results
For each academic decision category, dropout, guest enrollment, major change, and university transfer, multiple predictive models were developed and evaluated. The three best-performing models for each category were selected based on rigorous assessment using predefined evaluation metrics. The sections below present the selected models and their performance outcomes for each academic decision type.
Despite applying a comprehensive range of machine learning algorithms—including XGBoost, LR, and RF—alongside various sampling strategies to address class imbalance, the predictive performance for two academic decisions, namely major change and university transfer, remained consistently unsatisfactory. Detailed evaluation revealed that the underlying data matrices for these categories lacked the structural richness and discriminative features necessary for effective classification. In particular, the low signal-to-noise ratio and limited variation in predictor variables constrained the models’ ability to distinguish meaningful patterns. As a result, these two decision types were excluded from the final analysis to maintain the integrity and reliability of the reported findings.
Dropout prediction
To predict student dropout at TUMS, three machine learning models were evaluated using standard performance metrics, including accuracy, precision, recall, and F1-score. All models were trained on the same dataset, and the ran__smote model outperformed the others, achieving an overall accuracy of 95%. Notably, it attained an F1-score of 0.67 for the minority class (dropout), despite the significant class imbalance. To mitigate this imbalance, random undersampling was employed during training, which notably improved the model’s sensitivity to dropout cases (recall: 0.29 for class 1). This strategy enhanced the model’s capacity to detect students at risk, enabling earlier and more targeted interventions to reduce dropout rates.
As presented in Table 2, the selected model for predicting student dropout at TUMS demonstrated a high overall classification accuracy of 95%, indicating strong general performance across the dataset.
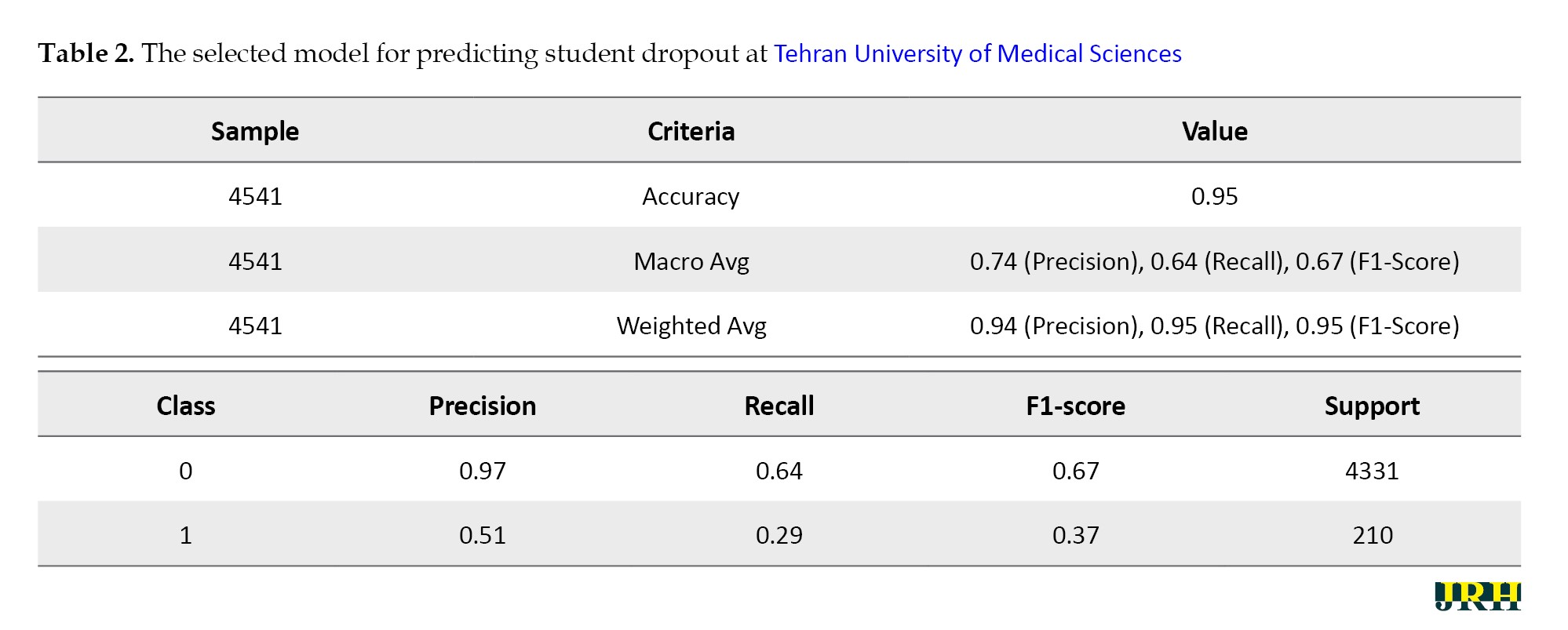
The weighted average precision, recall, and F1-score—all at 0.94 or higher—underscore the model’s effectiveness in correctly classifying the majority class (non-dropout). However, the macro-averaged metrics, which assign equal importance to each class regardless of frequency, reveal a notable disparity: the macro-average F1-score is 0.67, driven primarily by the model’s limited sensitivity to the minority class (dropout). Specifically, the F1-score for class 1 is just 0.37, with a recall of 0.29 and precision of 0.51, compared to 0.67, 0.64, and 0.97 for class 0, respectively. This performance gap highlights the ongoing challenge of class imbalance—despite attempts at mitigation—and underscores the need for further refinement, such as cost-sensitive learning or advanced resampling strategies, to enhance the model’s capacity to detect students truly at risk of attrition. Without such improvements, the practical utility of the model in early intervention contexts may remain constrained.
Guest student enrollment prediction
To predict student decisions regarding guest enrollment at TUMS, three statistical models were developed and assessed based on both overall performance and their effectiveness in identifying the minority class. The selected model, XGBoost, achieved an outstanding overall accuracy of 99%, alongside a macro-average F1-score of 0.85, indicating balanced performance across both classes. Notably, for the minority class (guest enrollment), the model attained an F1-score of 0.70, with a recall of 0.76 and precision of 0.64—substantially outperforming the alternative models in recognizing underrepresented cases. In parallel, the model maintained near-perfect performance for the majority class (non-guest students), with an F1-score of 1.00. These results underscore the model’s robustness in distinguishing between student subgroups and its potential utility for institutional forecasting, early identification, and strategic planning related to academic mobility policies (Table 3).
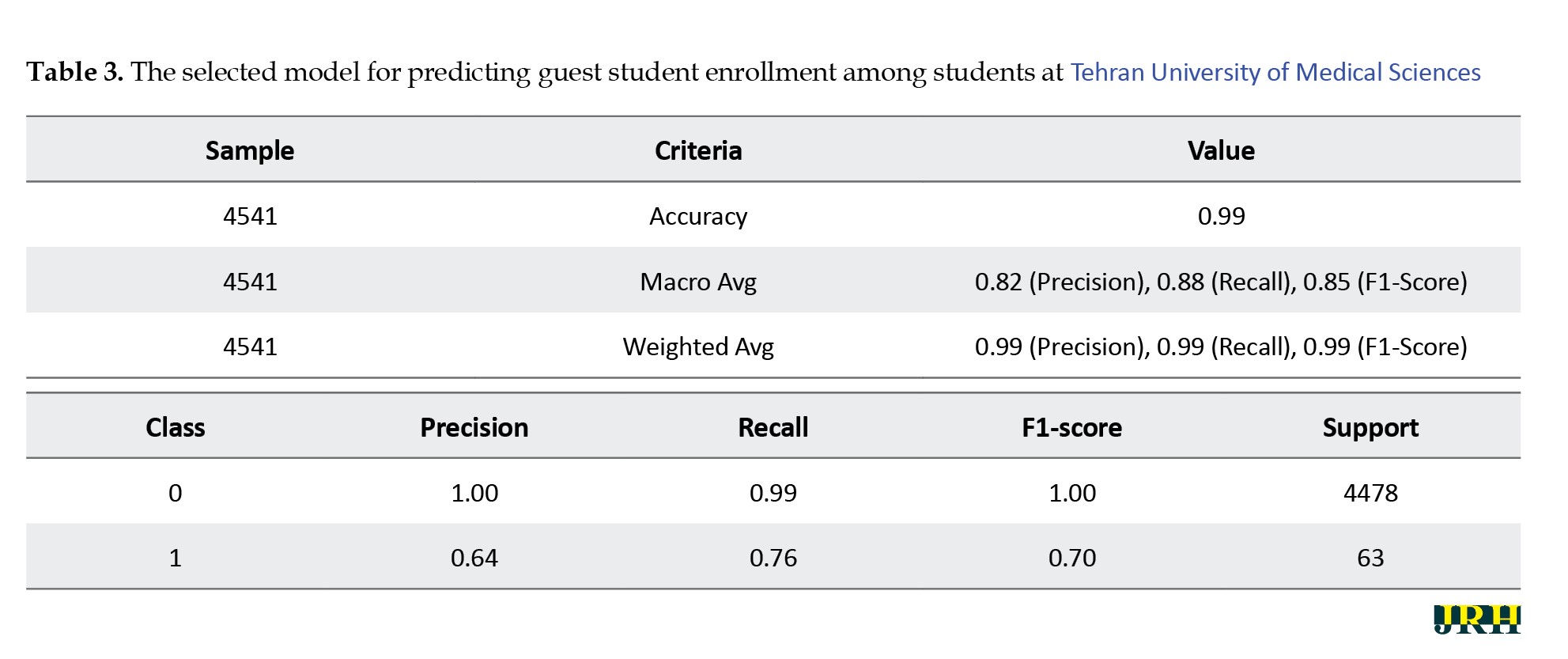
Table 3 illustrates the performance of the selected model in predicting guest student enrollment at TUMS, demonstrating exceptionally strong overall results. The model achieved an accuracy of 99%, with weighted averages for precision, recall, and F1-score, all reaching 0.99—reflecting near-perfect performance in classifying the majority class (non-guest students). Importantly, despite the limited representation of guest students (class 1), the model exhibited relatively strong predictive power for this minority class, achieving a recall of 0.76, a precision of 0.64, and an F1-score of 0.70. These metrics suggest that the model is not only effective in identifying students who did not pursue guest enrollment (F1-score=1.00 for class 0), but also demonstrates considerable capability in detecting those who did. The relatively high recall for class 1 is particularly valuable for institutional purposes, as it enables early identification of students likely to seek temporary enrollment elsewhere, supporting more responsive academic advising and policy interventions.
Table 4 provides a comparative overview of the predictive performance across the four academic decision categories.
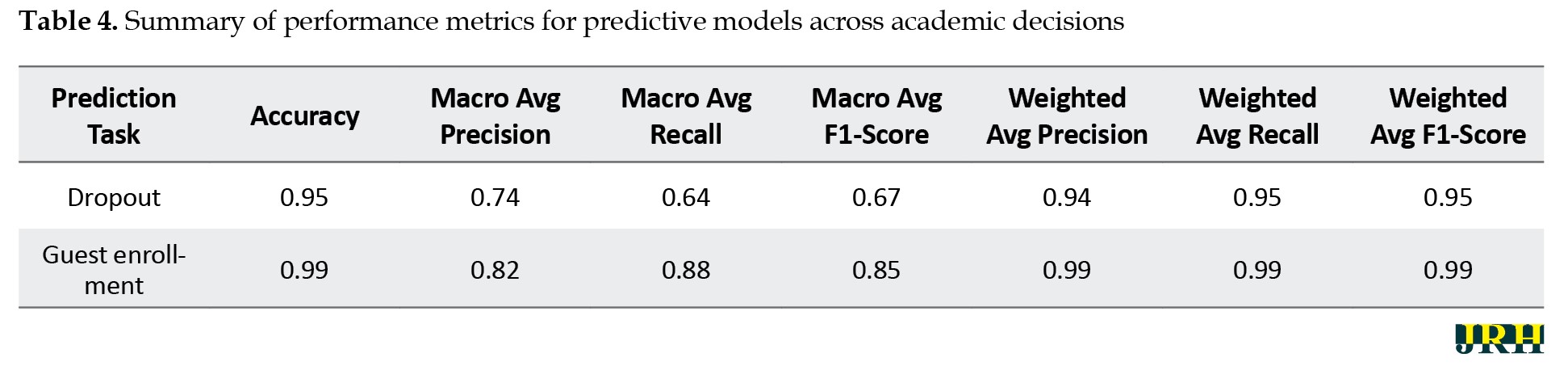
The table reports key evaluation metrics, including accuracy, macro-averaged scores (which give equal weight to each class), and weighted-averaged scores (which account for class imbalance). Among all models, the guest enrollment predictor achieved the strongest overall performance, while the transfer prediction model performed the weakest, particularly in detecting outcomes related to the minority class.
Figure 2 further illustrates, through a heatmap representation, the interrelationships and relative predictive importance of the analyzed variables.
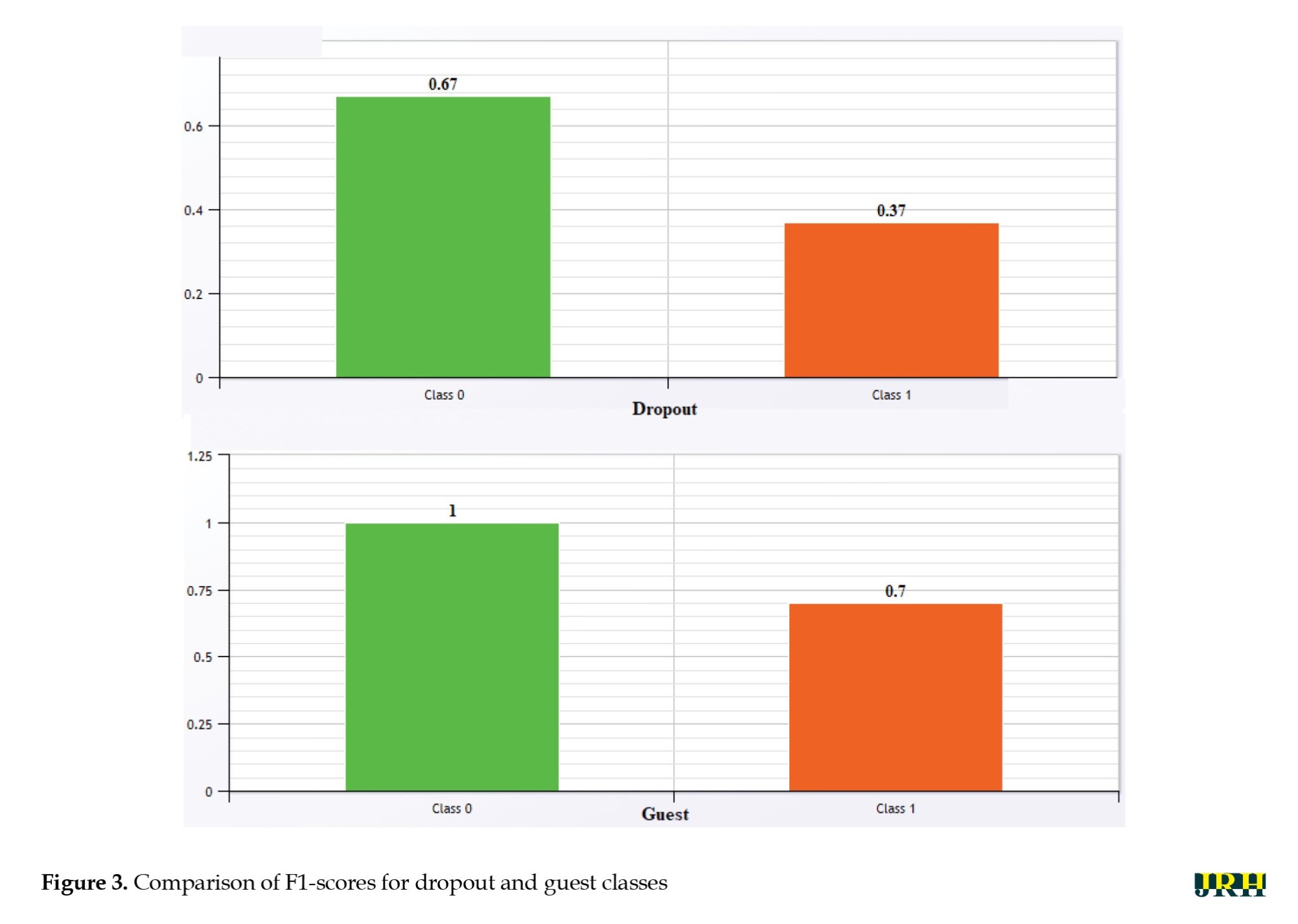
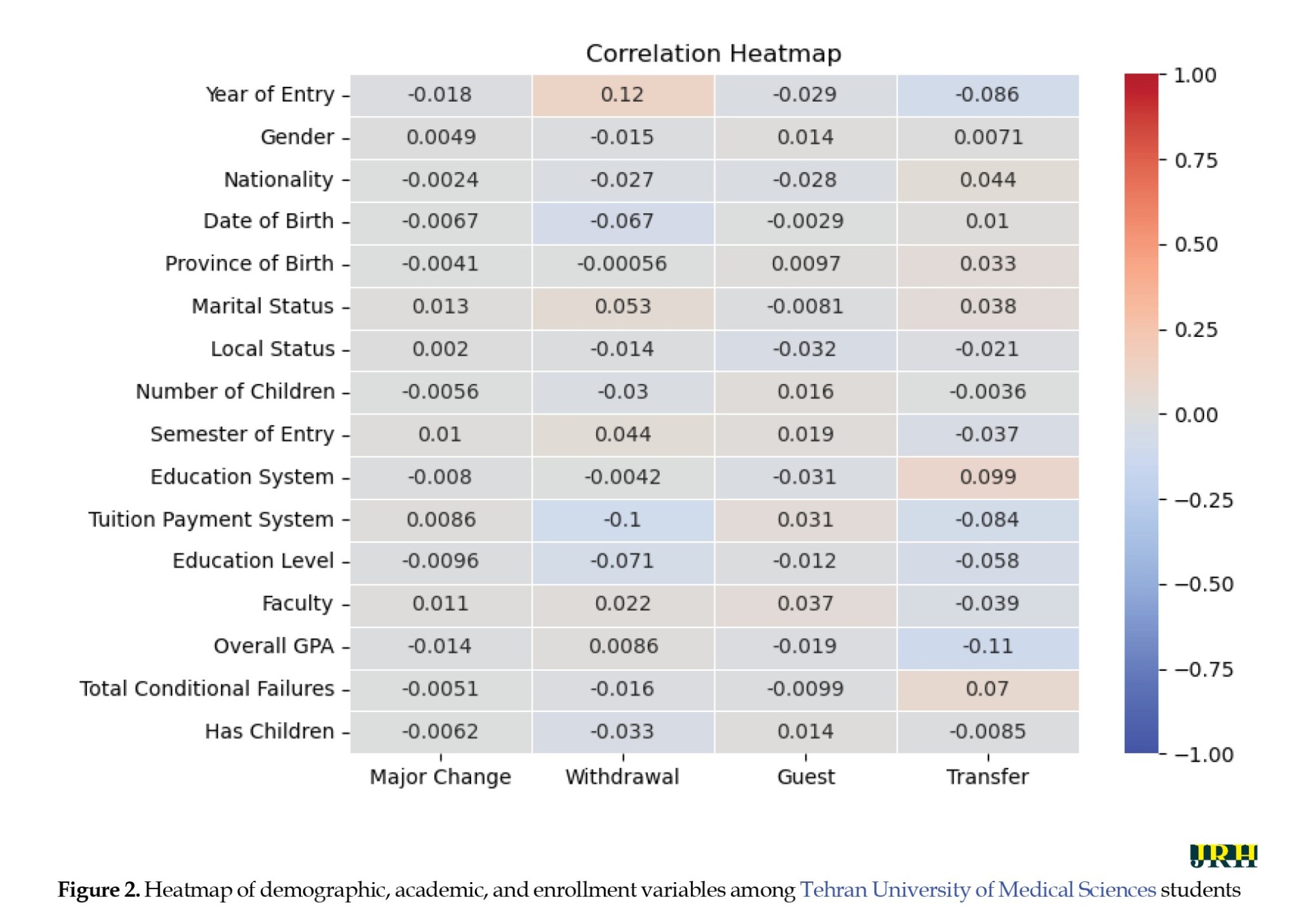 The correlation matrix revealed several noteworthy associations among student demographic, academic, and behavioral variables. As expected, birth year (based on date of birth) showed a strong negative correlation with marital status (r=–0.51) and number of children (r=0.35), indicating that older students are more likely to be married and have dependents. Parental status also showed an exceptionally strong positive correlation with the number of children (r=0.90), validating internal consistency. Nationality correlated highly with province of birth (r=0.45) and educational system (r=0.43), while showing a strong negative correlation with the tuition payment system (r=–0.45), possibly reflecting structural differences between domestic and international student profiles. Interestingly, GPA exhibited a moderate negative correlation with the number of academic probations (r=–0.51), which supports its validity as a performance indicator. Additionally, some weak but notable correlations emerge between guest enrollment and entry year (r=0.12), and between transfer decisions and faculty affiliation (r=0.04), suggesting the presence of institutional or cohort-specific patterns. Overall, while most variables exhibited low to moderate correlations, the matrix provided important clues about latent structures and justified the inclusion of certain predictors in the modeling process. The F1-scores for the dropout and guest decisions were compared in the bar chart shown in Figure 3.
The correlation matrix revealed several noteworthy associations among student demographic, academic, and behavioral variables. As expected, birth year (based on date of birth) showed a strong negative correlation with marital status (r=–0.51) and number of children (r=0.35), indicating that older students are more likely to be married and have dependents. Parental status also showed an exceptionally strong positive correlation with the number of children (r=0.90), validating internal consistency. Nationality correlated highly with province of birth (r=0.45) and educational system (r=0.43), while showing a strong negative correlation with the tuition payment system (r=–0.45), possibly reflecting structural differences between domestic and international student profiles. Interestingly, GPA exhibited a moderate negative correlation with the number of academic probations (r=–0.51), which supports its validity as a performance indicator. Additionally, some weak but notable correlations emerge between guest enrollment and entry year (r=0.12), and between transfer decisions and faculty affiliation (r=0.04), suggesting the presence of institutional or cohort-specific patterns. Overall, while most variables exhibited low to moderate correlations, the matrix provided important clues about latent structures and justified the inclusion of certain predictors in the modeling process. The F1-scores for the dropout and guest decisions were compared in the bar chart shown in Figure 3.
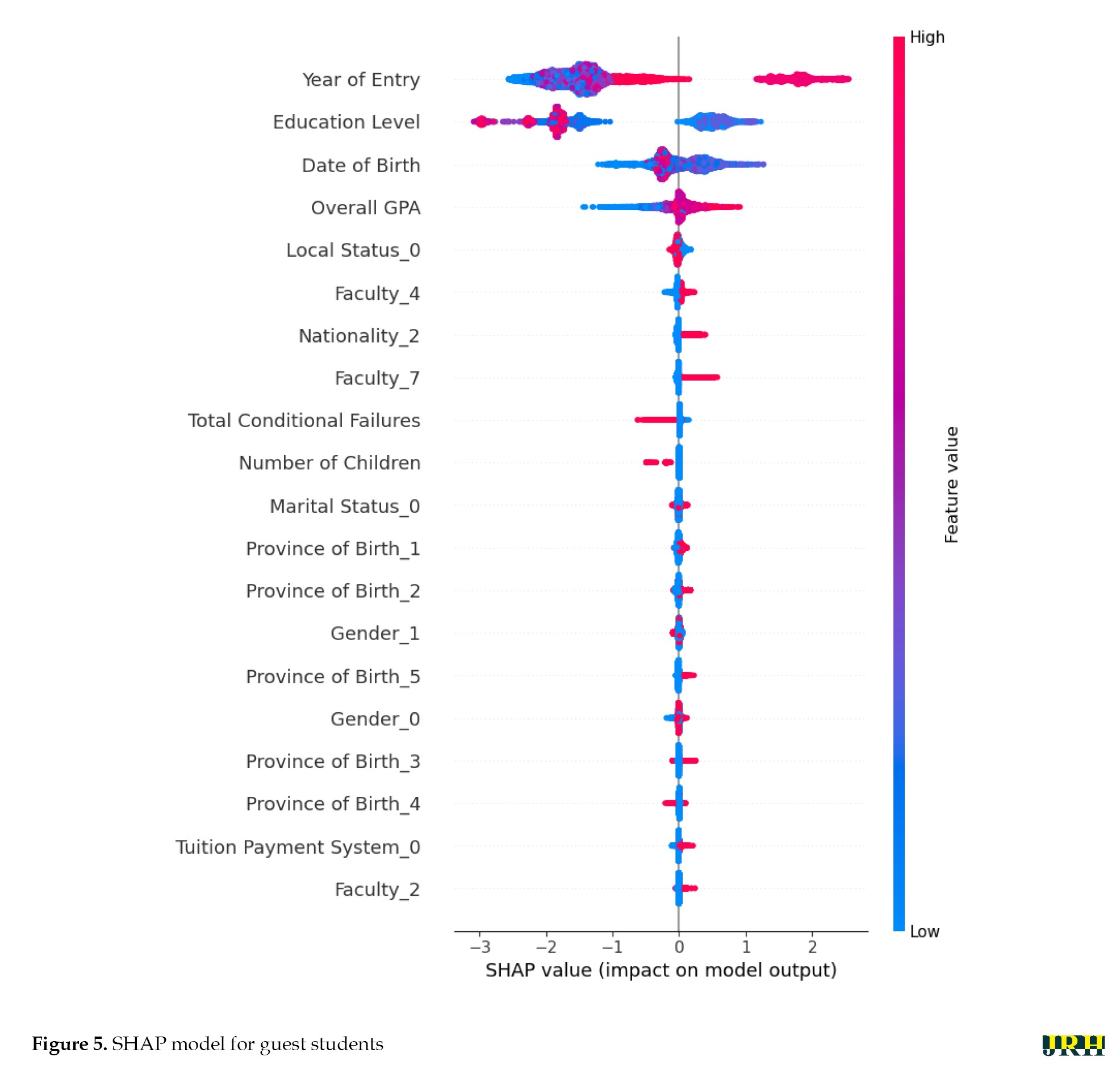
 Figures 4 and 5 illustrate the SHAP summary plot, presenting the relative importance and impact of each feature on the model’s output.
Figures 4 and 5 illustrate the SHAP summary plot, presenting the relative importance and impact of each feature on the model’s output.
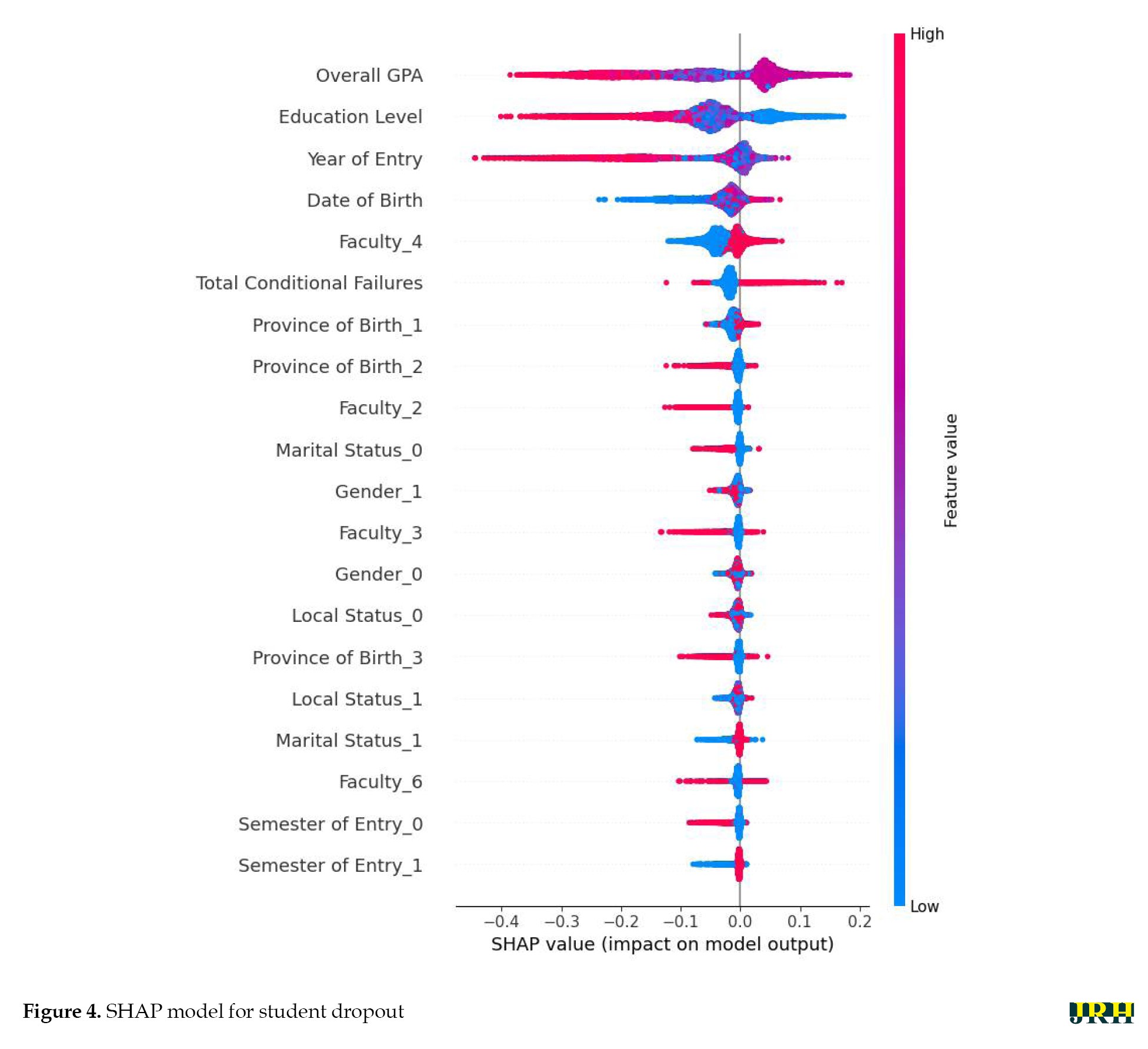
 Based on the provided SHAP values, the model’s prediction of a student’s academic outcome was highly influenced by their prior academic performance and background. The student’s overall GPA was the most significant feature, with a strong positive impact, indicating that a high historical GPA is the single largest predictor of a positive result from the model. This is followed by education level and year of entry, which also had substantial positive impacts. Conversely, a high number of total conditional failures was the most influential negative predictor, significantly decreasing the model’s output. Other features related to demographics and background (such as faculty, province of birth, local status, and gender) had smaller, yet discernible, impacts—both positive and negative—on the prediction, suggesting that these factors play a secondary but still relevant role in the model’s decision-making process.
Based on the provided SHAP values, the model’s prediction of a student’s academic outcome was highly influenced by their prior academic performance and background. The student’s overall GPA was the most significant feature, with a strong positive impact, indicating that a high historical GPA is the single largest predictor of a positive result from the model. This is followed by education level and year of entry, which also had substantial positive impacts. Conversely, a high number of total conditional failures was the most influential negative predictor, significantly decreasing the model’s output. Other features related to demographics and background (such as faculty, province of birth, local status, and gender) had smaller, yet discernible, impacts—both positive and negative—on the prediction, suggesting that these factors play a secondary but still relevant role in the model’s decision-making process.
The SHAP summary plot (Figure 5) elucidates the feature importance and directional impact on the model’s prediction of student academic outcome. The results indicated that temporal and academic performance factors were the most influential predictors. Specifically, year of entry was the most important feature, with more recent entry years correlating with a negative impact on the outcome. This was followed by education level and overall GPA, where higher values for both features exerted a strong positive effect. Date of birth also ranked highly, suggesting that older age at entry is associated with a more favorable prediction. Demographic and programmatic features, such as gender, faculty, and number of children demonstrably affected the model output but with comparatively lower magnitude and more mixed effects than the dominant academic and temporal variables.
Discussion
Tuition fees play a critical role in shaping students’ academic decisions, particularly in contexts where universities face financial constraints. Limited institutional resources often result in higher tuition burdens, influencing students’ choices of programs, fields of study, and even their ability to pursue higher education. As such, tuition is not merely a financial requirement but a decisive factor that directly impacts access, equity, and the overall trajectory of students’ educational paths [19-22]. The findings of this study provide compelling empirical support for the hypothesis that tuition fees are a significant determinant of students’ academic decision-making within the context of health-related higher education in Iran. Although predictive performance varied across academic outcomes, the overall success of AI-based models underscores their potential in developing early intervention strategies aimed at supporting at-risk students.
Among the models tested, the results presented in Table 2 highlight both the strengths and limitations of the selected model in predicting student dropout at TUMS. While the overall accuracy (0.95) and weighted average metrics (precision, recall, and F1-score all at 0.94–0.95) suggest that the model performed robustly at the aggregate level, a closer examination of class-specific metrics revealed a substantial performance gap between majority and minority classes. The model demonstrated high precision (0.97) and a reasonable F1-score (0.67) for the majority class (non-dropout), yet its recall for the minority class (dropout) dropped sharply to 0.29, with an F1-score of only 0.37. This discrepancy underscores the model’s limited sensitivity in detecting students at risk of attrition—an issue likely exacerbated by the significant class imbalance and possibly by unobserved confounders within the input features. These findings indicate that while the model is effective in correctly identifying students who remain enrolled, it may fail to adequately capture the complex and often latent indicators associated with dropout. Therefore, further refinement is needed, potentially through cost-sensitive learning, advanced feature engineering, or incorporation of longitudinal behavioral data, to enhance minority class prediction and support more equitable and actionable early warning systems. These results are consistent with prior findings that underscore the role of financial pressures in shaping dropout behavior. For instance, a study [23] identified limited financial resources as a key predictor of academic non-persistence, and another one [24] emphasized tuition-related challenges as a primary dropout factor. Notably, a study [25] projected that a 30% rise in tuition fees could lead to a 69% decline in student continuation rates.
The results in Table 3 demonstrate the strong predictive performance of the selected model in identifying guest student. The model achieved an exceptional overall accuracy of 99%, with nearly perfect weighted average precision, recall, and F1-score (all at 0.99), reflecting its high reliability in classifying the dominant group of non-guest students. More importantly, the model showed relatively strong performance for the minority class (guest students), achieving a recall of 0.76 and an F1-score of 0.70, which are considerably higher than typical results observed in imbalanced classification contexts. This suggests that the model not only avoids overfitting to the majority class but also retains a reasonable degree of sensitivity to underrepresented cases. Nevertheless, the precision for class 1 remains modest (0.64), indicating a moderate rate of false positives when predicting guest enrollment. While this trade-off may be acceptable in early intervention systems where recall is prioritized, it also highlights the need for further calibration to improve precision without sacrificing sensitivity. Overall, the model offers promising utility for institutional planning and proactive academic advising, particularly in identifying students who are likely to seek guest enrollment and may benefit from timely support.
The clinical relevance of our findings lies in their potential to enhance academic resilience and workforce continuity in health professions education. By identifying tuition-related academic vulnerabilities—such as increased risk of dropout or program switching—institutions can proactively intervene to support students in high-stakes, resource-intensive programs, like medicine, nursing, and pharmacy. This is particularly vital in systems facing physician and healthcare worker shortages, where training disruptions can have downstream effects on public health capacity. Tailored interventions, such as financial counseling or academic mentorship triggered by predictive models, can help ensure that financial constraints do not derail the academic paths of future healthcare professionals—thereby safeguarding long-term clinical service provision and equity in access to medical education.
Conclusion
This study employed a comparative machine learning framework to explore the influence of tuition fees on four critical academic decisions—dropout, major change, guest enrollment, and institutional transfer—within the domain of health-related higher education in Iran. Drawing on real-world data from TUMS, the findings of this study highlight the potential of machine learning models to support early identification of critical academic decisions among university students. The selected models demonstrated strong predictive performance in two key domains: student dropout and guest enrollment. While the dropout model achieved high overall accuracy, its limited sensitivity to minority cases underscores the persistent challenge of class imbalance in educational data. In contrast, the guest enrollment model performed robustly across both majority and minority classes, offering valuable insights for institutional forecasting and student advising. However, attempts to model two other academic decisions—major change and university transfer—yielded unsatisfactory results, primarily due to structural limitations in the data matrices and insufficient predictive signal. These findings emphasize the importance of data quality, class distribution, and contextual complexity in the development of effective predictive systems for higher education.
By simultaneously modeling multiple academic outcomes—including those often neglected in prior studies—this research significantly expands the application of AI in academic policy design. It also highlights the complex and multifaceted role of tuition fees in shaping student trajectories, especially in resource-constrained health education systems.
Policy recommendations
Data-Informed Tuition Strategies: policymakers in higher education should adopt tuition pricing frameworks that are sensitive to students’ socioeconomic realities. Tiered tuition schemes, sliding-scale models, or tuition caps based on income brackets may reduce the financial burden on vulnerable students and improve retention.
Early-warning systems for at-risk students: universities should integrate machine learning–based early identification systems into their academic management platforms. These systems can detect patterns of financial distress or academic disengagement, enabling proactive support measures, such as tuition deferrals, financial counseling, or academic mentorship.
Cross-sector data integration: to improve the predictive power and contextual relevance of academic risk models, higher education institutions should seek ethical access to non-academic variables—such as household income, financial aid records, mental health indicators, and parental education. Secure data-sharing agreements with relevant ministries (e.g. health, welfare, or labor) may be required. Targeted Support Programs: support interventions should be diversified beyond traditional academic assistance. Personalized financial guidance, mental health services, and career counseling—especially for students in critical transition points, such as major switching or transfer—can buffer the impact of financial stress. Revisiting National Tuition Policy in Medical Education: given the public-good nature of medical education and the societal demand for healthcare professionals, policymakers should reconsider the extent to which tuition fees serve as a sustainable funding mechanism. Expanded public investment, tuition reimbursement programs, or service-based scholarships may be more equitable alternatives.
Limitations
This study, while offering valuable insights into the tuition-related academic decision-making of students in health-related higher education, is subject to several limitations that warrant careful consideration.
First, the dataset was exclusively drawn from TUMS, a leading institution in Iran’s higher education system. Although the university provides a robust case study, the institutional specificity may limit the generalizability of the findings to other academic environments, both within Iran and internationally. Future studies incorporating multi-institutional or cross-national datasets would be essential to validate and extend the applicability of the present results. Second, issues related to class imbalance and limited sample size—particularly in categories, such as institutional transfer—posed significant challenges to model performance and stability. Despite the implementation of advanced resampling techniques, predictive accuracy for minority classes remained suboptimal, underscoring the need for larger and more balanced datasets in future investigations.
Third, the absence of several critical contextual variables due to privacy constraints and limited data access represents a key limitation. Variables, such as household income, financial aid status, parental education level, and psychological stress were not included in the modeling process, despite their well-established relevance to students’ academic trajectories. The inclusion of such features could substantially enhance model precision and offer richer, more nuanced insights into the interplay between financial burden and academic decision-making.
Lastly, the study did not incorporate macroeconomic indicators, such as inflation rates, tuition policy reforms, or currency fluctuations—factors that can significantly influence students’ financial behavior and educational planning, especially in volatile economic settings. Accounting for these broader dynamics in future models could increase both the robustness and real-world relevance of predictive outcomes. Acknowledging these limitations provides a framework for methodological refinement and sets a clear agenda for future research aimed at developing more comprehensive, context-sensitive, and policy-relevant models in educational data science.
Research recommendations
Application of transformer-based models: future studies could explore the use of transformer architectures (e.g. BERT, TabTransformer, time series transformers) to model longitudinal academic behavior and tuition-sensitive decision-making across multiple semesters or institutions.
Integration of attention mechanisms: implementing attention-based models may help identify the most influential features or time-points in students’ academic trajectories, thereby improving both interpretability and intervention design.
Development of hybrid deep learning models: Combining convolutional neural networks (CNNs) and long short-term memory networks (LSTMs) could enable the modeling of both temporal sequences and structured institutional data, capturing complex decision-making processes among students.
Cross-national comparative modeling with scalable architectures: Employing transfer learning or federated learning approaches may allow models to generalize across different economic and educational contexts, enhancing global applicability and equity-focused policy design.
Simulation of dynamic tuition policies using reinforcement learning: Reinforcement learning frameworks could be applied to simulate adaptive tuition strategies that optimize both institutional sustainability and student retention outcomes.
Multi-output learning for joint decision prediction: Future research could adopt multi-task or multi-output learning models to simultaneously predict correlated academic outcomes (e.g. dropout and major change), enabling a more holistic approach to student behavior modeling.
Modeling interactions via graph neural networks (GNNs): Using graph-based deep learning could capture the complex interdependencies between students, academic departments, and course structures, improving the accuracy of tuition-related behavior predictions.
Multimodal learning combining quantitative and qualitative data: Integrating structured institutional data with unstructured text sources—such as surveys, motivational statements, or social media posts—may offer deeper insights into students’ financial stress, motivation, and intent.
Ethical Considerations
Compliance with ethical guidelines
The Ethics Committee of the TUMS approved the study (ethics code: IR.TUMS.MEDICINE.REC.1402.691). All methods were carried out following relevant guidelines and regulations. The confidentiality of the participants’ information was assured.
Funding
This research was supported by Tehran University of Medical Sciences (Grant No: 1402-4-101-69607). The funders had no role in study design, data collection and analysis, the decision to publish, or preparation of the manuscript.
Authors' contributions
All authors contributed equally to the conception and design of the study, data collection and analysis, interpretation of the results, and drafting of the manuscript. Each author approved the final version of the manuscript for submission.
Conflict of interest
The authors declared no conflicts of interest.
Acknowledgments
The authors would like to thank the Vice Chancellor of Education Affairs of Tehran University of Medical Sciences for providing secure access to the data.
References
Over the past two decades, the financial stability of many nations has been profoundly disrupted by recurrent global crises, notably the financial collapses of 2001 and 2008. These disruptions triggered widespread economic downturns, significantly affecting public investment across multiple sectors. The higher education system has been among the hardest hit, with funding declines intensifying following the COVID-19 pandemic, a trend increasingly documented in the literature [1]. In Iran, while health policymakers have long maintained that medical education and healthcare services are public goods and thus insulated from traditional market mechanisms, the escalating burden of health expenditures and the growing public debt resulting from state obligations have progressively introduced market-oriented rationalities into health sector governance [2]. This paradigm shift has substantially impacted medical education financing, shifting the cost burden toward students and families. As a consequence, tuition fees have emerged as the primary revenue stream for many universities operating under financial constraints, particularly in low- and middle-income countries [3].
This transition has exacerbated regional disparities in educational access and affordability. More critically, the rising cost of education now directly shapes students’ academic trajectories, influencing decisions, such as program withdrawal, field switching, guest enrollment, or institutional transfer. While existing research has explored the effects of socioeconomic and demographic factors on students’ academic decision-making, the specific role of tuition fees—especially in the context of health-related higher education in Iran—remains underexamined. This gap is particularly striking given the structural transformation of university funding models in recent years and the increased volatility in students’ educational paths under financial stress. Recent advances in artificial intelligence (AI), particularly in educational data mining, offer novel opportunities to analyze such complex phenomena. AI-driven models enable the identification of subtle, non-linear patterns in large educational datasets, providing actionable insights for university governance and national policy. Among the prominent AI methods, logistic regression (LR) is valued for its interpretability, yet limited in handling complex, non-linear relationships. In contrast, artificial neural networks (ANNs) excel in modeling such patterns but often lack transparency. Decision trees (DTs) provide rule-based clarity and work effectively with categorical data but are susceptible to overfitting. Random forests (RFs), as ensemble learners, enhance predictive performance and generalizability, though they may sacrifice interpretability relative to simpler models. Despite the growing utility of these tools, tuition-driven academic decision-making has received limited empirical scrutiny within Iranian medical universities. This study aimed to fill this gap by employing comparative machine learning approaches to analyze the predictive role of tuition fees in shaping student decisions at Tehran University of Medical Sciences.
Specifically, the study investigated whether financial pressure from tuition contributes significantly to four pivotal academic outcomes: dropout, major change, guest enrollment, and institutional transfer. To guide the empirical analysis, the study proposes the following hypotheses:
H1) Tuition fees are a statistically significant predictor of student dropout. H2) Tuition fees significantly influence students’ decisions to change their academic major. H3) Higher tuition fees are associated with an increased likelihood of guest enrollment. H4) There is a significant relationship between tuition costs and the probability of transferring to another university.
By integrating AI-based modeling with the policy-relevant context of health education financing, this study offers both methodological and substantive contributions. It not only enhances our understanding of tuition-related vulnerabilities among students but also provides actionable evidence for institutional and governmental stakeholders aiming to promote educational equity and resilience.
Literature review
The relationship between tuition fees and students’ academic decisions has been the subject of substantial scholarly debate, often yielding paradoxical findings. On the one hand, researchers, such as Brooks and Waters [4] argue that rising tuition costs exert a deterrent effect on enrollment, particularly among students from disadvantaged backgrounds. On the other hand, Lan and Winters [5] report minimal or statistically insignificant impacts of tuition increases on student behavior. This divergence in empirical outcomes has prompted the emergence of conceptual frameworks, such as Heller’s “tuition dilemma” and “tuition paradox” [6], which seek to reconcile the contradictory evidence by highlighting the contextual and psychological mediators of tuition sensitivity.
Parallel to this discourse, a growing body of research has turned to AI as a means of modeling and predicting academic outcomes, particularly student attrition. AI-based predictive analytics have shown promise in uncovering latent patterns in educational data, enabling early interventions aimed at reducing dropout rates. For instance, Mubarak et al. [7] reported an accuracy rate of 84% in predicting early attrition within online learning environments using AI classifiers. Gismondi and Huisman [8] achieved a remarkable 98.97% prediction accuracy for student dropout using multilayer neural networks at the National University of San Pedro, while Agrusti et al. [9] employed deep neural networks and reported a 93.4% accuracy rate in dropout detection.
Several studies have also demonstrated the comparative advantages of tree-based algorithms. Kemper et al. [10] found that decision tree models significantly outperformed traditional LR in predicting student withdrawal behavior, attaining an accuracy of 95%. Similarly, Behr et al. [11] applied RF algorithms and achieved an 86% accuracy rate for early-stage dropout prediction. Haiyang et al. [12] utilized a time-series classification model, yielding an 84% accuracy rate in identifying dropout trajectories.
Further evidence in favor of decision tree–based approaches is offered by Limsathitwong et al. [13], who highlighted their superior performance, reporting an 80% accuracy rate. Berens et al. [14] found that dropout prediction accuracy increased over time, reaching 90% after the fourth semester in public universities, and up to 95% in universities of applied sciences. Dass et al. [15] demonstrated that RFs could accurately predict student dropout decisions in MOOC environments with 88% precision. Complementing these findings, Solis et al. [16] conducted a comprehensive comparison of machine learning models—including RFs, neural networks, support vector machines, and LR—and concluded that RFs yielded the highest predictive accuracy at 91%, offering a robust solution for identifying at-risk students.
Despite these promising advances, most existing studies have focused narrowly on dropout as a single academic outcome and have primarily been conducted in Western or online education contexts. There remains a critical gap in the literature regarding the multifaceted impact of tuition fees on a broader set of academic decisions—particularly within the context of resource-constrained, health-related higher education systems in countries, like Iran. Addressing this gap through the application of comparative AI modeling not only enhances methodological diversity but also contributes to the development of context-sensitive strategies for academic risk mitigation and policy design.
Novelty and contribution
This study pioneers a multi-dimensional, machine learning–driven framework to model the impact of tuition fees on four distinct academic decision pathways—dropout, major change, guest enrollment, and institutional transfer—within the underexplored context of health-related higher education in Iran. In contrast to prevailing research that predominantly isolates student dropout and relies on conventional statistical modeling, this work integrated a suite of advanced AI algorithms with state-of-the-art resampling strategies to address data imbalance and enhance model robustness, particularly in predicting low-frequency academic transitions.
Leveraging a longitudinal dataset from Tehran University of Medical Sciences—one of the country’s most prominent academic institutions in the health sector—the study moves beyond abstract modeling to deliver empirically grounded, policy-relevant insights. By situating tuition-related decisions within a real-world, resource-constrained environment, the research sheds light on the nuanced ways where financial pressure translates into academic vulnerability.
Furthermore, the comparative analysis of AI models not only identifies the most accurate and interpretable predictive strategies but also provides an operational framework for early-warning systems targeting at-risk students. This dual contribution—methodological innovation and practical applicability—positions the study as a significant advancement in both educational data science and policy-making for equity-driven, sustainable health education systems in emerging economies.
Methods
To empirically examine the proposed hypotheses, we employed a range of machine learning algorithms to model and predict the influence of tuition fees on key academic outcomes, including student dropout, changes in field of study, guest enrollment, and university transfer. This study systematically assessed the extent to which tuition costs shape academic decision-making by leveraging diverse AI-based modeling techniques. Figure 1 shows a diagram of the stages of the research method.
Data collection
This study utilized a longitudinal dataset encompassing the entire student population of TUMS across 12 academic schools, spanning the years 2016 to 2023. The dataset reflects the university’s institutional data collection framework and includes detailed demographic and academic records.
The number of students enrolled in each academic unit was as follows: International Campus (2,822), School of Public Health (1,917), School of Nursing and Midwifery (2,460), School of Medicine (9,326), School of Rehabilitation Sciences (954), School of Pharmacy (1,468), School of Dentistry (1,276), School of Traditional Iranian Medicine (121), School of Paramedical Sciences (1,683), School of Nutrition and Dietetics (304), School of Advanced Medical Technologies (310), and School of Research and Technology (60).
In terms of gender distribution, the dataset included 9,868 male students (43.5%) and 12,832 female students (56.5%), totaling 22,700 enrolled individuals over the eight years.
Variables
The independent variables of the study are detailed in Table 1.
The dependent variables represent key academic decisions and are structured as binary outcomes. These include:
The decision to drop out, the decision to enroll as a guest student, the decision to transfer to another institution, and the decision to change academic fields.
Evaluation metrics
To assess the performance of the classification models, three standard evaluation metrics were employed: Mean absolute error (MAE), mean squared error (MSE), and root mean squared error (RMSE). These metrics quantify the average discrepancy between predicted values and actual observations.
MAE measures the average of the absolute differences between the predicted and actual values (Equation 1):
Where ypred represents the predicted value, yactual refers to the actual value, and n is the number of data points, and |x| denotes the absolute value of x. MSE measures the average of the squared differences between the predicted and actual values (Equation 2):
The square root of the MSE is the RMSE (Equation 3):
RMSE is often favored over MSE due to its superior interpretability, as it retains the same units as the dependent variable, thereby enabling more direct comparisons with observed values. Although lower values in both metrics typically reflect improved model performance, the choice of evaluation metric should ultimately depend on the specific analytical goals and contextual priorities of the study.
Algorithms used
LR
LR is a statistical modeling method used to assess the relationship between a categorical dependent variable (such as the presence or absence of an outcome) and one or more independent variables. Often referred to as a logit model, it is widely utilized in domains, such as medical diagnosis, social sciences, and predictive analytics due to its simplicity and interpretability [15].
ANNs
ANNs are data-driven modeling techniques capable of learning complex, non-linear relationships from representative datasets without requiring explicit mathematical descriptions of the underlying system. Their flexibility and adaptability make them particularly effective in reducing uncertainty and improving predictive accuracy and decision-making across a wide range of applications [16].
Decision tree
The decision tree algorithm is a supervised machine learning technique used for both classification and regression tasks. It is widely valued for its high interpretability, as it generates human-readable decision rules derived from the training data. DTs can handle various data types, including both numerical and categorical variables, and their hierarchical structure provides a transparent framework for understanding the reasoning behind predictions [17].
Random forest (RF)
RF is an ensemble learning method that constructs multiple DTs, each trained on random subsets of the data, and combines their outputs to improve prediction accuracy and robustness. By aggregating diverse models, RF mitigates the risk of overfitting commonly associated with single DTs. Although this approach enhances overall performance, it may reduce interpretability compared to individual models [18].
Given the imbalanced distribution of outcome classes in the dataset, several strategies were employed to address class imbalance. In classification tasks where the minority class is significantly underrepresented, predictive models tend to perform poorly on that class, often favoring the majority class. To mitigate this issue, the following resampling techniques were implemented:
In this study, we systematically evaluated the performance of three widely used machine learning algorithms—XGBoost, LR, and RF—for predicting student academic decisions. Each model was trained using specific hyperparameter configurations (Appendix 1, 2 and 3) to ensure optimal performance.
Given the inherent class imbalance in the dataset (i.e. the unequal distribution of target categories), we applied and compared five different sampling strategies to improve model fairness and accuracy. These included synthetic minority over-sampling technique (SMOTE), Tomek links (TOM), Tomek links combined with edited nearest neighbors (TEEN), random under-sampling (UNDER), and a baseline model with no sampling (none). For each combination of the model, hyperparameters, and sampling technique, we assessed predictive performance using standard evaluation metrics, and selected the best-performing configuration for each target outcome. The final models and their corresponding optimal sampling methods are reported in the Results section.
To facilitate interpretability and transparency, the models were trained on a set of well-defined parameters capturing demographic, academic, and institutional dimensions of student status. These included continuous variables, such as age, GPA, and number of probationary semesters, as well as categorical variables, such as academic degree, school affiliation, course type (tuition-paying vs free), marital status, gender, semester of entry, birth province, and native status (Tehran vs non-Tehran residents). The year of study and academic semester were treated as ordinal variables to reflect progression over time. Together, these parameters provided a comprehensive profile of each student, enabling the models to learn patterns associated with tuition sensitivity and academic decision-making in a nuanced and data-driven manner.
Results
For each academic decision category, dropout, guest enrollment, major change, and university transfer, multiple predictive models were developed and evaluated. The three best-performing models for each category were selected based on rigorous assessment using predefined evaluation metrics. The sections below present the selected models and their performance outcomes for each academic decision type.
Despite applying a comprehensive range of machine learning algorithms—including XGBoost, LR, and RF—alongside various sampling strategies to address class imbalance, the predictive performance for two academic decisions, namely major change and university transfer, remained consistently unsatisfactory. Detailed evaluation revealed that the underlying data matrices for these categories lacked the structural richness and discriminative features necessary for effective classification. In particular, the low signal-to-noise ratio and limited variation in predictor variables constrained the models’ ability to distinguish meaningful patterns. As a result, these two decision types were excluded from the final analysis to maintain the integrity and reliability of the reported findings.
Dropout prediction
To predict student dropout at TUMS, three machine learning models were evaluated using standard performance metrics, including accuracy, precision, recall, and F1-score. All models were trained on the same dataset, and the ran__smote model outperformed the others, achieving an overall accuracy of 95%. Notably, it attained an F1-score of 0.67 for the minority class (dropout), despite the significant class imbalance. To mitigate this imbalance, random undersampling was employed during training, which notably improved the model’s sensitivity to dropout cases (recall: 0.29 for class 1). This strategy enhanced the model’s capacity to detect students at risk, enabling earlier and more targeted interventions to reduce dropout rates.
As presented in Table 2, the selected model for predicting student dropout at TUMS demonstrated a high overall classification accuracy of 95%, indicating strong general performance across the dataset.
The weighted average precision, recall, and F1-score—all at 0.94 or higher—underscore the model’s effectiveness in correctly classifying the majority class (non-dropout). However, the macro-averaged metrics, which assign equal importance to each class regardless of frequency, reveal a notable disparity: the macro-average F1-score is 0.67, driven primarily by the model’s limited sensitivity to the minority class (dropout). Specifically, the F1-score for class 1 is just 0.37, with a recall of 0.29 and precision of 0.51, compared to 0.67, 0.64, and 0.97 for class 0, respectively. This performance gap highlights the ongoing challenge of class imbalance—despite attempts at mitigation—and underscores the need for further refinement, such as cost-sensitive learning or advanced resampling strategies, to enhance the model’s capacity to detect students truly at risk of attrition. Without such improvements, the practical utility of the model in early intervention contexts may remain constrained.
Guest student enrollment prediction
To predict student decisions regarding guest enrollment at TUMS, three statistical models were developed and assessed based on both overall performance and their effectiveness in identifying the minority class. The selected model, XGBoost, achieved an outstanding overall accuracy of 99%, alongside a macro-average F1-score of 0.85, indicating balanced performance across both classes. Notably, for the minority class (guest enrollment), the model attained an F1-score of 0.70, with a recall of 0.76 and precision of 0.64—substantially outperforming the alternative models in recognizing underrepresented cases. In parallel, the model maintained near-perfect performance for the majority class (non-guest students), with an F1-score of 1.00. These results underscore the model’s robustness in distinguishing between student subgroups and its potential utility for institutional forecasting, early identification, and strategic planning related to academic mobility policies (Table 3).
Table 3 illustrates the performance of the selected model in predicting guest student enrollment at TUMS, demonstrating exceptionally strong overall results. The model achieved an accuracy of 99%, with weighted averages for precision, recall, and F1-score, all reaching 0.99—reflecting near-perfect performance in classifying the majority class (non-guest students). Importantly, despite the limited representation of guest students (class 1), the model exhibited relatively strong predictive power for this minority class, achieving a recall of 0.76, a precision of 0.64, and an F1-score of 0.70. These metrics suggest that the model is not only effective in identifying students who did not pursue guest enrollment (F1-score=1.00 for class 0), but also demonstrates considerable capability in detecting those who did. The relatively high recall for class 1 is particularly valuable for institutional purposes, as it enables early identification of students likely to seek temporary enrollment elsewhere, supporting more responsive academic advising and policy interventions.
Table 4 provides a comparative overview of the predictive performance across the four academic decision categories.
The table reports key evaluation metrics, including accuracy, macro-averaged scores (which give equal weight to each class), and weighted-averaged scores (which account for class imbalance). Among all models, the guest enrollment predictor achieved the strongest overall performance, while the transfer prediction model performed the weakest, particularly in detecting outcomes related to the minority class.
Figure 2 further illustrates, through a heatmap representation, the interrelationships and relative predictive importance of the analyzed variables.
The SHAP summary plot (Figure 5) elucidates the feature importance and directional impact on the model’s prediction of student academic outcome. The results indicated that temporal and academic performance factors were the most influential predictors. Specifically, year of entry was the most important feature, with more recent entry years correlating with a negative impact on the outcome. This was followed by education level and overall GPA, where higher values for both features exerted a strong positive effect. Date of birth also ranked highly, suggesting that older age at entry is associated with a more favorable prediction. Demographic and programmatic features, such as gender, faculty, and number of children demonstrably affected the model output but with comparatively lower magnitude and more mixed effects than the dominant academic and temporal variables.
Discussion
Tuition fees play a critical role in shaping students’ academic decisions, particularly in contexts where universities face financial constraints. Limited institutional resources often result in higher tuition burdens, influencing students’ choices of programs, fields of study, and even their ability to pursue higher education. As such, tuition is not merely a financial requirement but a decisive factor that directly impacts access, equity, and the overall trajectory of students’ educational paths [19-22]. The findings of this study provide compelling empirical support for the hypothesis that tuition fees are a significant determinant of students’ academic decision-making within the context of health-related higher education in Iran. Although predictive performance varied across academic outcomes, the overall success of AI-based models underscores their potential in developing early intervention strategies aimed at supporting at-risk students.
Among the models tested, the results presented in Table 2 highlight both the strengths and limitations of the selected model in predicting student dropout at TUMS. While the overall accuracy (0.95) and weighted average metrics (precision, recall, and F1-score all at 0.94–0.95) suggest that the model performed robustly at the aggregate level, a closer examination of class-specific metrics revealed a substantial performance gap between majority and minority classes. The model demonstrated high precision (0.97) and a reasonable F1-score (0.67) for the majority class (non-dropout), yet its recall for the minority class (dropout) dropped sharply to 0.29, with an F1-score of only 0.37. This discrepancy underscores the model’s limited sensitivity in detecting students at risk of attrition—an issue likely exacerbated by the significant class imbalance and possibly by unobserved confounders within the input features. These findings indicate that while the model is effective in correctly identifying students who remain enrolled, it may fail to adequately capture the complex and often latent indicators associated with dropout. Therefore, further refinement is needed, potentially through cost-sensitive learning, advanced feature engineering, or incorporation of longitudinal behavioral data, to enhance minority class prediction and support more equitable and actionable early warning systems. These results are consistent with prior findings that underscore the role of financial pressures in shaping dropout behavior. For instance, a study [23] identified limited financial resources as a key predictor of academic non-persistence, and another one [24] emphasized tuition-related challenges as a primary dropout factor. Notably, a study [25] projected that a 30% rise in tuition fees could lead to a 69% decline in student continuation rates.
The results in Table 3 demonstrate the strong predictive performance of the selected model in identifying guest student. The model achieved an exceptional overall accuracy of 99%, with nearly perfect weighted average precision, recall, and F1-score (all at 0.99), reflecting its high reliability in classifying the dominant group of non-guest students. More importantly, the model showed relatively strong performance for the minority class (guest students), achieving a recall of 0.76 and an F1-score of 0.70, which are considerably higher than typical results observed in imbalanced classification contexts. This suggests that the model not only avoids overfitting to the majority class but also retains a reasonable degree of sensitivity to underrepresented cases. Nevertheless, the precision for class 1 remains modest (0.64), indicating a moderate rate of false positives when predicting guest enrollment. While this trade-off may be acceptable in early intervention systems where recall is prioritized, it also highlights the need for further calibration to improve precision without sacrificing sensitivity. Overall, the model offers promising utility for institutional planning and proactive academic advising, particularly in identifying students who are likely to seek guest enrollment and may benefit from timely support.
The clinical relevance of our findings lies in their potential to enhance academic resilience and workforce continuity in health professions education. By identifying tuition-related academic vulnerabilities—such as increased risk of dropout or program switching—institutions can proactively intervene to support students in high-stakes, resource-intensive programs, like medicine, nursing, and pharmacy. This is particularly vital in systems facing physician and healthcare worker shortages, where training disruptions can have downstream effects on public health capacity. Tailored interventions, such as financial counseling or academic mentorship triggered by predictive models, can help ensure that financial constraints do not derail the academic paths of future healthcare professionals—thereby safeguarding long-term clinical service provision and equity in access to medical education.
Conclusion
This study employed a comparative machine learning framework to explore the influence of tuition fees on four critical academic decisions—dropout, major change, guest enrollment, and institutional transfer—within the domain of health-related higher education in Iran. Drawing on real-world data from TUMS, the findings of this study highlight the potential of machine learning models to support early identification of critical academic decisions among university students. The selected models demonstrated strong predictive performance in two key domains: student dropout and guest enrollment. While the dropout model achieved high overall accuracy, its limited sensitivity to minority cases underscores the persistent challenge of class imbalance in educational data. In contrast, the guest enrollment model performed robustly across both majority and minority classes, offering valuable insights for institutional forecasting and student advising. However, attempts to model two other academic decisions—major change and university transfer—yielded unsatisfactory results, primarily due to structural limitations in the data matrices and insufficient predictive signal. These findings emphasize the importance of data quality, class distribution, and contextual complexity in the development of effective predictive systems for higher education.
By simultaneously modeling multiple academic outcomes—including those often neglected in prior studies—this research significantly expands the application of AI in academic policy design. It also highlights the complex and multifaceted role of tuition fees in shaping student trajectories, especially in resource-constrained health education systems.
Policy recommendations
Data-Informed Tuition Strategies: policymakers in higher education should adopt tuition pricing frameworks that are sensitive to students’ socioeconomic realities. Tiered tuition schemes, sliding-scale models, or tuition caps based on income brackets may reduce the financial burden on vulnerable students and improve retention.
Early-warning systems for at-risk students: universities should integrate machine learning–based early identification systems into their academic management platforms. These systems can detect patterns of financial distress or academic disengagement, enabling proactive support measures, such as tuition deferrals, financial counseling, or academic mentorship.
Cross-sector data integration: to improve the predictive power and contextual relevance of academic risk models, higher education institutions should seek ethical access to non-academic variables—such as household income, financial aid records, mental health indicators, and parental education. Secure data-sharing agreements with relevant ministries (e.g. health, welfare, or labor) may be required. Targeted Support Programs: support interventions should be diversified beyond traditional academic assistance. Personalized financial guidance, mental health services, and career counseling—especially for students in critical transition points, such as major switching or transfer—can buffer the impact of financial stress. Revisiting National Tuition Policy in Medical Education: given the public-good nature of medical education and the societal demand for healthcare professionals, policymakers should reconsider the extent to which tuition fees serve as a sustainable funding mechanism. Expanded public investment, tuition reimbursement programs, or service-based scholarships may be more equitable alternatives.
Limitations
This study, while offering valuable insights into the tuition-related academic decision-making of students in health-related higher education, is subject to several limitations that warrant careful consideration.
First, the dataset was exclusively drawn from TUMS, a leading institution in Iran’s higher education system. Although the university provides a robust case study, the institutional specificity may limit the generalizability of the findings to other academic environments, both within Iran and internationally. Future studies incorporating multi-institutional or cross-national datasets would be essential to validate and extend the applicability of the present results. Second, issues related to class imbalance and limited sample size—particularly in categories, such as institutional transfer—posed significant challenges to model performance and stability. Despite the implementation of advanced resampling techniques, predictive accuracy for minority classes remained suboptimal, underscoring the need for larger and more balanced datasets in future investigations.
Third, the absence of several critical contextual variables due to privacy constraints and limited data access represents a key limitation. Variables, such as household income, financial aid status, parental education level, and psychological stress were not included in the modeling process, despite their well-established relevance to students’ academic trajectories. The inclusion of such features could substantially enhance model precision and offer richer, more nuanced insights into the interplay between financial burden and academic decision-making.
Lastly, the study did not incorporate macroeconomic indicators, such as inflation rates, tuition policy reforms, or currency fluctuations—factors that can significantly influence students’ financial behavior and educational planning, especially in volatile economic settings. Accounting for these broader dynamics in future models could increase both the robustness and real-world relevance of predictive outcomes. Acknowledging these limitations provides a framework for methodological refinement and sets a clear agenda for future research aimed at developing more comprehensive, context-sensitive, and policy-relevant models in educational data science.
Research recommendations
Application of transformer-based models: future studies could explore the use of transformer architectures (e.g. BERT, TabTransformer, time series transformers) to model longitudinal academic behavior and tuition-sensitive decision-making across multiple semesters or institutions.
Integration of attention mechanisms: implementing attention-based models may help identify the most influential features or time-points in students’ academic trajectories, thereby improving both interpretability and intervention design.
Development of hybrid deep learning models: Combining convolutional neural networks (CNNs) and long short-term memory networks (LSTMs) could enable the modeling of both temporal sequences and structured institutional data, capturing complex decision-making processes among students.
Cross-national comparative modeling with scalable architectures: Employing transfer learning or federated learning approaches may allow models to generalize across different economic and educational contexts, enhancing global applicability and equity-focused policy design.
Simulation of dynamic tuition policies using reinforcement learning: Reinforcement learning frameworks could be applied to simulate adaptive tuition strategies that optimize both institutional sustainability and student retention outcomes.
Multi-output learning for joint decision prediction: Future research could adopt multi-task or multi-output learning models to simultaneously predict correlated academic outcomes (e.g. dropout and major change), enabling a more holistic approach to student behavior modeling.
Modeling interactions via graph neural networks (GNNs): Using graph-based deep learning could capture the complex interdependencies between students, academic departments, and course structures, improving the accuracy of tuition-related behavior predictions.
Multimodal learning combining quantitative and qualitative data: Integrating structured institutional data with unstructured text sources—such as surveys, motivational statements, or social media posts—may offer deeper insights into students’ financial stress, motivation, and intent.
Ethical Considerations
Compliance with ethical guidelines
The Ethics Committee of the TUMS approved the study (ethics code: IR.TUMS.MEDICINE.REC.1402.691). All methods were carried out following relevant guidelines and regulations. The confidentiality of the participants’ information was assured.
Funding
This research was supported by Tehran University of Medical Sciences (Grant No: 1402-4-101-69607). The funders had no role in study design, data collection and analysis, the decision to publish, or preparation of the manuscript.
Authors' contributions
All authors contributed equally to the conception and design of the study, data collection and analysis, interpretation of the results, and drafting of the manuscript. Each author approved the final version of the manuscript for submission.
Conflict of interest
The authors declared no conflicts of interest.
Acknowledgments
The authors would like to thank the Vice Chancellor of Education Affairs of Tehran University of Medical Sciences for providing secure access to the data.
References
- Rehman WU, Degirmen S, Waseem F. Propensity for and quality of intellectual capital divulgence across the BRICS banking sector: A knowledge-based perspective from emerging economies. Journal of the Knowledge Economy. 2021; 1-28. [DOI:10.1007/s13132-021-00730-z]
- Ngepah N, Saba CS, Mabindisa NG. Human capital and economic growth in South Africa: A cross-municipality panel data analysis. South African Journal of Economic and Management Sciences. 2021; 24(1):1-1. [DOI:10.4102/sajems.v24i1.3577]
- Jaquette O, Kramer DA, Curs BR. Growing the pie? The effect of responsibility center management on tuition revenue. The Journal of Higher Education. 2018; 89(5):637-76. [DOI:10.1080/00221546.2018.1434276]
- Brooks R, Waters J. Fees, funding and overseas study: Mobile UK students and educational inequalities. Sociological Research Online. 2011; 16(2):19-28. [DOI:10.5153/sro.2362]
- Lan Y, Winters JV. Did the DC tuition assistance grant program cause out-of-state tuition to increase? Economics Bulletin. 2011; 31(3):2444-53. [Link]
- Heller DE. The states and public higher education policy: Affordability, access, and accountability. Baltimore: JHU Press; 2001. [Link]
- Mubarak AA, Cao H, Zhang W. Prediction of students’ early dropout based on their interaction logs in online learning environment. Interactive Learning Environments. 2022; 30(8):1414-33. [DOI:10.1080/10494820.2020.1727529]
- Gismondi HE, Huiman LV. Multilayer neural networks for predicting academic dropout at the national university of santa-peru. Paper presented at: 2021 International Symposium on Accreditation of Engineering and Computing Education (ICACIT). 4 November 2021; Lima, Peru. [DOI:10.1109/ICACIT53544.2021.9612507]
- Agrusti F, Mezzini M, Bonavolontà G. Deep learning approach for predicting university dropout: A case study at Roma Tre University. Journal of e-Learning and Knowledge Society. 2020; 16(1):44-54. [Link]
- Kemper L, Vorhoff G, Wigger BU. Predicting student dropout: A machine learning approach. European Journal of Higher Education. 2020; 10(1):28-47. [DOI:10.1080/21568235.2020.1718520]
- Behr A, Giese M, Theune K. Early prediction of university dropouts-a random forest approach. Jahrbücher für Nationalökonomie und Statistik. 2020; 240(6):743-89. [DOI:10.1515/jbnst-2019-0006]
- Haiyang L, Wang Z, Benachour P, Tubman P. A time series classification method for behaviour-based dropout prediction. Paper presented at: 2018 IEEE 18th international conference on advanced learning technologies (ICALT). 9 July 2018. IEEE. [DOI:10.1109/ICALT.2018.00052]
- Limsathitwong K, Tiwatthanont K, Yatsungnoen T. Dropout prediction system to reduce discontinue study rate of information technology students. Paper presented at: 2018 5th International Conference on Business and Industrial Research (ICBIR). 17 May, 2018. IEEE. [DOI:10.1109/ICBIR.2018.8391176]
- Berens J, Schneider K, Görtz S, Oster S, Burghoff J. Early detection of students at risk. predicting student dropouts using administrative student data and machine learning methods. CESIFO WP. 2018; 7259. [DOI:10.2139/ssrn.3275433]
- Dass S, Gary K, Cunningham J. Predicting student dropout in self-paced MOOC course using random forest model. Information. 2021; 12(11):476. [DOI:10.3390/info12110476]
- Solis M, Moreira T, Gonzalez R, Fernandez T, Hernandez M. Perspectives to predict dropout in university students with machine learning. Paper presented at: 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI).18 July 2018. IEEE. [DOI:10.1109/IWOBI.2018.8464191] [PMID]
- Nick TG, Campbell KM. Logistic regression. Topics in Biostatistics. 2007; 273-301. [DOI:10.1007/978-1-59745-530-5_14] [PMID]
- Coppola Jr EA, Rana AJ, Poulton MM, Szidarovszky F, Uhl VW. A neural network model for predicting aquifer water level elevations. Groundwater. 2005; 43(2):231-41. [DOI:10.1111/j.1745-6584.2005.0003.x] [PMID]
- Keykha A. Tuition fees and academic decisions: Unpacking the impact on the students of tehran university’s management faculties. Interdisciplinary Journal of Management Studies. 2024; 17(3):781-97. [Link]
- Naderi Roshnavand A, Khodaei E, Geraeinejad G, Keykha A. [Exploring the role of tuition on students’ academic decisions: A meta-synthesis study (Persian)]. Educational Measurement and Evaluation Studies. 2023; 13(43):115-60. [DOI:10.22034/emes.2023.1972209.2435]
- Khodaei E, Geraeinejad G., Keykha A. [The study of policy components in the tuition economy in the public sector: A meta-synthesis of selected studies (Persian)]. Public Organizations Management. 2023; 11(3):35-52. [Link]
- Naderi A, Geraeinejad G, Khodaei E, Keykha A. An analysis of the effective factors in students’ academic decisions with a cognitive approach (case study: Tehran University Students). Journal of Management and Planning in Educational System. 2024; 17(2):9-40. [DOI:10.48308/mpes.2024.234452.1422]
- El Massari H, Gherabi N, Mhammedi S, Ghandi H, Qanouni F, Bahaj M. An ontological model based on machine learning for predicting breast cancer. International Journal of Advanced Computer Science and Applications. 2022; 13(7):108-15. [DOI:10.14569/IJACSA.2022.0130715]
- Su Y, Weng K, Lin C, Zheng Z. An improved random forest model for the prediction of dam displacement. Ieee Access. 2021; 9:9142-53. [DOI:10.1109/ACCESS.2021.3049578]
- Bäulke L, Grunschel C, Dresel M. Student dropout at university: A phase-oriented view on quitting studies and changing majors. European Journal of Psychology of Education. 2022; 37(3):853-76. [DOI:10.1007/s10212-021-00557-x]
Type of Study: Orginal Article |
Subject:
● Artificial Intelligence
Received: 2025/06/7 | Accepted: 2025/09/14 | Published: 2025/12/31
Received: 2025/06/7 | Accepted: 2025/09/14 | Published: 2025/12/31
| Rights and permissions | |
 |
This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License. |
This is an open access article distributed under the terms of the Creative Commons Attribution License (CC-By-NC), which permits use, distribution, and reproduction in any medium, provided the original work is properly cited and is not used for commercial purposes.
Contact Information
